
{kind=link}
What is a Robots.txt File?
Robots.txt is a file that contains instructions for search engine crawlers, sometimes known as bots. It tells search engines whether or not to crawl specific pages or sections of a website. This instruction set is typically followed by search engines (Google, Bing, and Yahoo). A robots.txt file tells Google or other web crawlers that you do not want particular pages indexed.
How Does a Robots.txt File Work?
Search engines have two primary functions:
- Discover content by crawling the web.
- Indexing the content so that information-seeking searchers can find it from the search result.
Search engines crawl sites by following links from one website to another, eventually scanning billions of links and web pages.
The search crawler will seek a robots.txt file after arriving at a website. If a robots.txt file is discovered, the search crawler will scan it before proceeding through the pages. The robots.txt file specifies how the search engine should crawl a site. The file can contain instructions that prevent a user-agent from crawling some information on the site.
What is the Significance of the Robots.txt File?
The robots.txt file is quite significant for SEO purposes in general. Robots.txt is required for larger websites to give search engines specific instructions on what content they should not access.
There are three primary reasons why you should utilize a robots.txt file.
Block Non-Public and Duplicate Pages
You might not want some pages on your website to be indexed. For instance, you may have a staging version of a page, internal search results pages, duplicate pages, or even a login page. These pages are required, although they are not required to be indexed and discovered by search engines. This is an ideal situation for robots.txt to prevent crawlers and bots from accessing these pages.
Crawl Budget
The number of pages Google will crawl on your site at any given time is referred to as the “crawl budget.” The amount may vary depending on your site’s size, health, and number of backlinks. If you’re experiencing difficulty getting all of your pages indexed, you may have a crawl budget issue. And pages that are not indexed will not rank for anything. The Robots.txt file can help Googlebot (Google’s web crawler) detect irrelevant pages. As a result, Googlebot can spend more of your crawl budget on pages that are important to you.
Prevent Resource Indexing
You may wish Google to omit multimedia items such as PDFs, videos, and photos from search results. Perhaps you want to keep some resources private, or you want Google to prioritize more critical stuff. In that scenario, the simplest option to prevent them from being indexed is to use robots.txt.
Robots.txt File Syntax
A typical robots.txt file might consist of several components and aspects, such as:
- User-agent
- Command to “allow” or “disallow”
- Crawl-delay
- Sitemap
- Comments
User-Agent
Each search engine has its user agent. Website administrators can offer special instructions for particular bots in the robots.txt file by writing separate instructions for user agents.
For example, if you want a specific website to appear in Bing search results but not in Google, you can put two instruction sets in the robots.txt file. One set of directives will be with “User-agent: Bingbot” while the other will be with “User-agent: Googlebot.”
User-agent: bingbot
Allow: /Folder1/
User-agent: Googlebot
Disallow: /Folder1/
However, we can utilize the (*) wildcard to give directives to all user-agents.
User-agent: *
Disallow: /
There are hundreds of different user agents, however here are a few that are important for SEO:
| Search Engines | Type | User-agent |
| Desktop | Googlebot | |
| Smartphone | Googlebot | |
| News | Googlebot-News | |
| Videos | Googlebot-Video | |
| Images | Googlebot-Image | |
| AdSense Mobile | Mediapartners-Google | |
| AdSense Desktop | Mediapartners-Google | |
| Bing | Desktop and Mobile | Bingbot |
| Bing | Predecessor of Bingbot | MSNBot |
| Bing | Images and Videos | MSNBot-Media |
| Bing | Bing Ads | AdIdxBot |
| Bing | Page Snapshots | BingPreview |
| Baidu | Desktop | Baiduspider |
| Baidu | Advertisements | Baiduspider-ads |
| Baidu | Image Search | Baiduspider-image |
| Baidu | News Search | Baiduspider-news |
| Baidu | Video Search | Baiduspider-video |
| Yandex | Desktop | YandexBot |
| Yandex | Mobile | YandexMobileBot |
| Yandex | All Crawling | Yandex |
| Yandex | Advertising | YandexDirect |
| Yandex | Media | YandexMedia |
| Yandex | Images | YandexImages |
| Yandex | Advertising | YaDirectFetcher |
| Yandex | News | YandexNews |
| Yandex | Calendar | YandexCalendar |
| Yahoo! | All Search | Slurp |
| DuckDuckGo | Search | DuckDuckBot |
| AOL | Search | aolbuild |
Disallow Directive
In the robots.txt file, the Disallow command is the most commonly used. Depending on the rule, it instructs a search engine not to crawl a given path or collection of URLs. If you want to restrict access to several portions of a website, there can be one or more lines of disallowing rules.
Disallowed pages aren’t technically “hidden” – they’re merely uninteresting to the ordinary Google or Bing user, thus they’re not shown to them.
If you want your full website blocked or not crawled by search engines, you may use the below disallow all syntax in the robots.txt file.
User-agent: *
Disallow: /
This will tell all search engines to crawl the entire website. There is no rule on restrictions.
User-agent: *
Disallow:
This will tell search engine Google not to crawl your website.
User-agent: googlebot
Disallow: /
All search engines are directed not to visit the /wp-admin/ directory in this case.
User-agent: *
Disallow: /wp-admin/
In this case, all search engine bots will be denied access to /wp-admin/, but Bingbot will be denied access to Disclaimer.
User-agent: *
Disallow: /wp-admin/
User-agent: bingbot
Disallow: /Disclaimer/
Allow Directive
Allow directive can counteract a Disallow directive. For example, if you are disallowing a directory but want to allow a file under that directory to be accessed. The robots.txt file would be:
Here search engines can access 123.JPG. But they can’t access any other file inside /photos.
User-agent: *
Disallow: /photos
Allow: /Photos/123.jpg
Avoid using wildcards when combining the Allow and Disallow directives, since this may result in contradicting directives. This directive is supported by both Google and Bing.
Crawl-Delay Directive
The crawl delay directive slows the rate at which a bot crawls your website. Because the crawl delay directive is an unofficial guideline, not all search engines will follow it.
Google and Baidu do not follow this directive. Bing and Yahoo support the crawl delay directive. Basic syntax:
User-agent: bingbot
Disallow: /wp-admin/
crawl-delay: 5
Sitemap Protocol in Robots.txt File
The sitemap directive in the robots.txt file informs search engines where to find your Sitemap and allows different search engines to easily identify the URLs on your website. It is an alternative to submitting sitemaps to search engines using their webmaster tools. However, we strongly recommend you submit sitemaps to search engines.
The sitemap directive should be included at the bottom of your robots.txt file.
As an example, consider the following:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://itcheats.com/sitemap_index.xml
Comments
A robots.txt file can contain comments, however, they are only visible to humans and not bots, as everything following a hashtag is disregarded.
Comments can be valuable for a variety of reasons, including:
- Explains why some rules exist.
- Indicates which sections of a website the restrictions apply to.
- Describes what the regulations do.
How to Create or Edit a Robots.txt File?
Create and Edit Robots.txt File via cPanel
Using cPanel, you can create a robots.txt file. Navigate to the cPanel of your hosting provider. Locate the file manager and go to the website’s root directory (public_html). There, you can either create or edit the file.
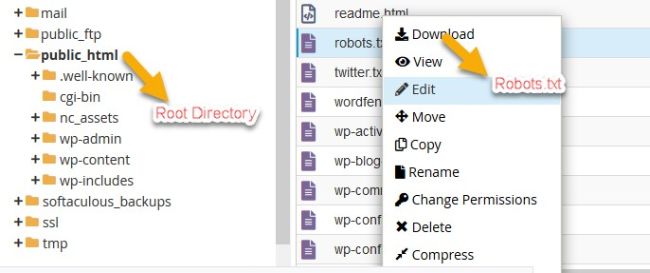
Robots.txt File in cPanel
Create and Edit Robots.txt File on WordPress
Creating a robots.txt file for WordPress is easy. You will need the Yoast SEO plugin to create or edit a robots.txt file in WordPress. Go to the Yoast dashboard, then to Tools and File Editor. The robots.txt file can now be seen and edited in the WordPress dashboard.
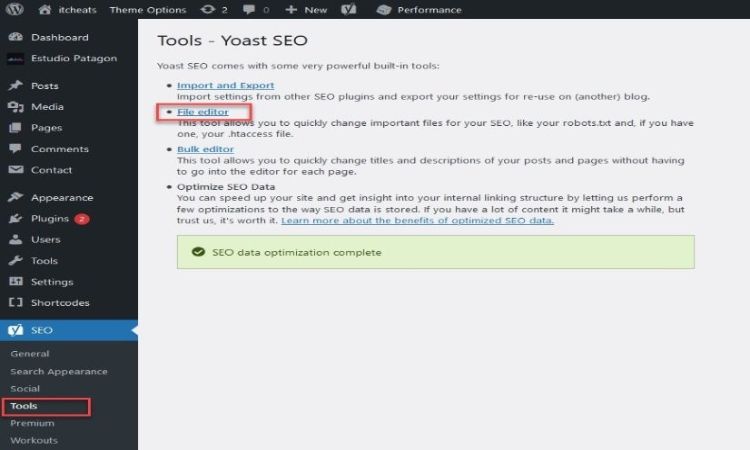
Create and Edit Robots.txt File on WordPress
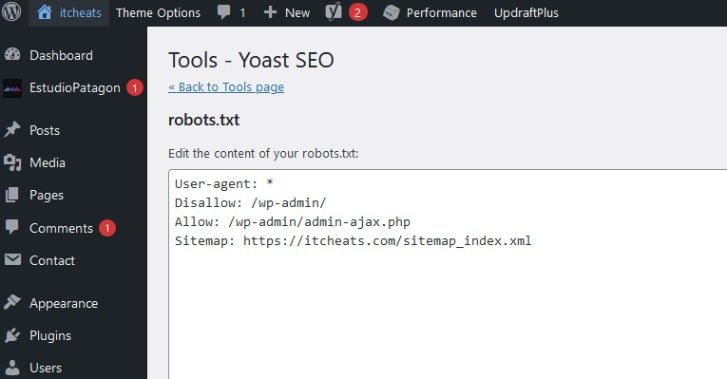
Create and Edit Robots.txt File on WordPress
Robots.txt File Generator
You can write down your website’s robots.txt file on a notepad. Or use a robots.txt generator for generating a file. Some free tools are:
How to Audit your Robots.txt File for Errors
Robots.txt errors can easily slide through the cracks, so keep a lookout for them. Check the “Coverage” report in Search Console regularly for robots.txt problems. Some of the errors you may encounter, what they mean, and how to resolve them are listed below.
Submitted URL Blocked by Robots.txt
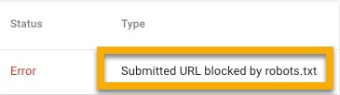
Submitted URL Blocked by Robots.txt
This signifies that robots.txt has blocked at least one of the URLs in your uploaded sitemap. No submitted pages should be blocked by robots.txt if your sitemap was properly created and excludes canonicalized, no indexed, and redirected pages. If they are, look into which pages are affected and make the necessary changes to your robots.txt file to remove the block for that page.
You can use Google’s robots.txt tester to determine which directive is preventing access to the content. Just be cautious when doing so. It’s simple to make errors that affect other sites and files.
Blocked by Robots.txt
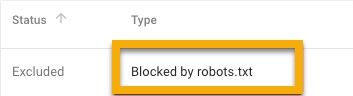
Blocked by Robots.txt
This signifies you have robots.txt-blocked content that Google isn’t presently indexing. Remove the crawl block in robots.txt if this content is significant and should be indexed. If you used robots.txt to exclude content from Google’s index, remove the crawl block and replace it with a robots meta tag or x-robots-header. That is the only way to ensure that information is not included in Google’s index.
Indexed, though Blocked by Robots.txt
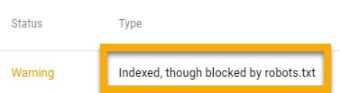
Indexed, though Blocked by Robots.txt
This implies that some of the robots.txt-blocked content are still indexed by Google. Again, if you want to remove this content from Google’s search results, robots.txt isn’t the way to go. To prevent indexing, remove the crawl block and use a meta robots tag or an x-robots-tag HTTP header.
If you accidentally blocked this content and wish to retain it in Google’s index, remove the crawl block in robots.txt. This may help to increase the visibility of the content in Google searches.
What are Regular Expressions and Wildcards in the Robots.txt?
The robots.txt standard does not “officially” accept regular expressions or wildcards; yet, all major search engines recognize it. Regular expressions may be used to match patterns, and the two primary characters that both Google and Bing follow are:
- The dollar symbol ($) that appears at the end of a URL
- * is a wildcard character that can represent any sequence of characters.
We have included examples of regular expressions and wildcards in the robots.txt file in the later section
Robots.txt File Best practices
- Check whether you’re restricting any content or parts of your website that you want crawling.
- Each directive should be used on a new line. Otherwise, it can confuse search engines.
Not Recommended
| User-agent: * Disallow: /directory1/ Disallow: /directory2/ |
Recommended:
|
User-agent: * Disallow: /images/ Disallow: /directory/ |
- Place the robots.txt file in the root directory of a website and name it robots.txt, for example, https://domainname.com/robots.txt. If the robots.txt file is not located in its default position, search engines will presume there are no instructions and will explore your website.
- You can use same the User-Agent multiple times. However, referring to it only once maintains things nice and straightforward and lowers the possibility of human error.
Not Recommended
|
User-agent: Googlebot Disallow: /about User-agent: Googlebot Disallow: /Terms & Conditions |
Recommended:
|
User-agent: Googlebot Disallow: /about Disallow: /Terms & Conditions |
- To apply a directive to all user-agents and match URL patterns, use wildcards (*). If you wanted to block search engines from accessing URLs with parameters, for example, you could potentially list them one by one.
Not Recommended:
|
User-agent: * Disallow: /List/shirts? Disallow: /List/pants? |
However, this is inefficient. It would be preferable to use a wildcard to simplify things.
Recommended:
|
User-agent: * Disallow: /List/*? |
The above example prevents all search engine bots from crawling all URLs containing a question mark in the /List/ subdirectory.
- You can use “$” to indicate the end of a URL. If you wish to prevent search engines from indexing all.png files on your site, for example, you may list them separately.
Not Recommended:
|
User-agent: * Disallow: /a.jpg Disallow: /b.jpg |
Recommended:
|
Instead, you can use this. User-agent: * Disallow: /*.png$ |
In this case, search engines are unable to access any URLs that finish in.png. That indicates they can’t access /example.png, but they can reach /example.png?id=1234567 because it doesn’t end with “.png”.
- Use “#” to add comments. Search engine crawlers will ignore anything that starts with “#”. You can use this to your advantage. You can add comments to remember any point.
- Use different Robots.txt files for different subdomains.
Common Questions about Robots.txt Files
Maximum Size of a Robots.txt File
Google presently maintains a 500 kibibyte file size restriction for robots.txt files (KiB).
Where is Robots.txt in WordPress?
Exactly in the same place as every website. yourdomain.com/robots.txt.
Is the Ordering of Rules Important?
The sequence of the rules is unimportant. However, the longest matching path rule is used first, taking priority over the less specific shorter rule. If both pathways have the same length, less stringent criteria will be used.
Can a Robots.txt File Prevent the Indexing of Content?
Robots.txt file can not 100% prevent indexing of content. Search Engines do ignore Robots.txt files sometimes. The only way to prevent your content from being indexed is to include a noindex meta tag on the page.
Robots.txt is a simple yet effective file. If used correctly, it can have a good influence on SEO. If you use it carelessly, you’ll live to regret it.
I am curious to find out what blog platform you are working
with? I’m experiencing some small security problems with my latest blog
and I would like to find something more secure. Do you have any recommendations?
I am using WordPress. You can try it.
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this.
Please let me know if you run into anything. I truly enjoy
reading your blog and I look forward to your new updates.
I wanted to thank you for this very good read!! I absolutely loved every little bit of it.
I have got you bookmarked to check out new stuff you post…